この記事は、2022年10月28日に開催されたDIST.37「マークアップな夜」での発表「マークアップのわかり方」をもとにしたものです。当日は話せなかった内容も大幅に追加しています。

現代における「マークアップ」とはどのような行為なのか。いかにそれと向き合っていけばいいのか。そういったことについて考えてみます。

マークアップの議論においては、「マークアップには正解がない」という意見が決まって出ます。正解がないと言うならば、たいていなんであってもそうです。たとえばCSSやJavaScriptの書き方には「正解」があるのかと考えてみると、必ずしもそうではありません。
しかし、ことさらマークアップにおいてこれがよく言われる理由としては、妥当性を判断する基準がわからない、ということでしょう。

というのも、CSSなら望む通りの見た目になればとりあえずOKだし、JavaScriptでも意図した通りの振る舞いをすればまあいいだろう、という判断ができます。けれどHTMLでは、divを使おうがbuttonを使おうが、何が変わるのかがその場でわからなくてどうしようもないのかもしれません。
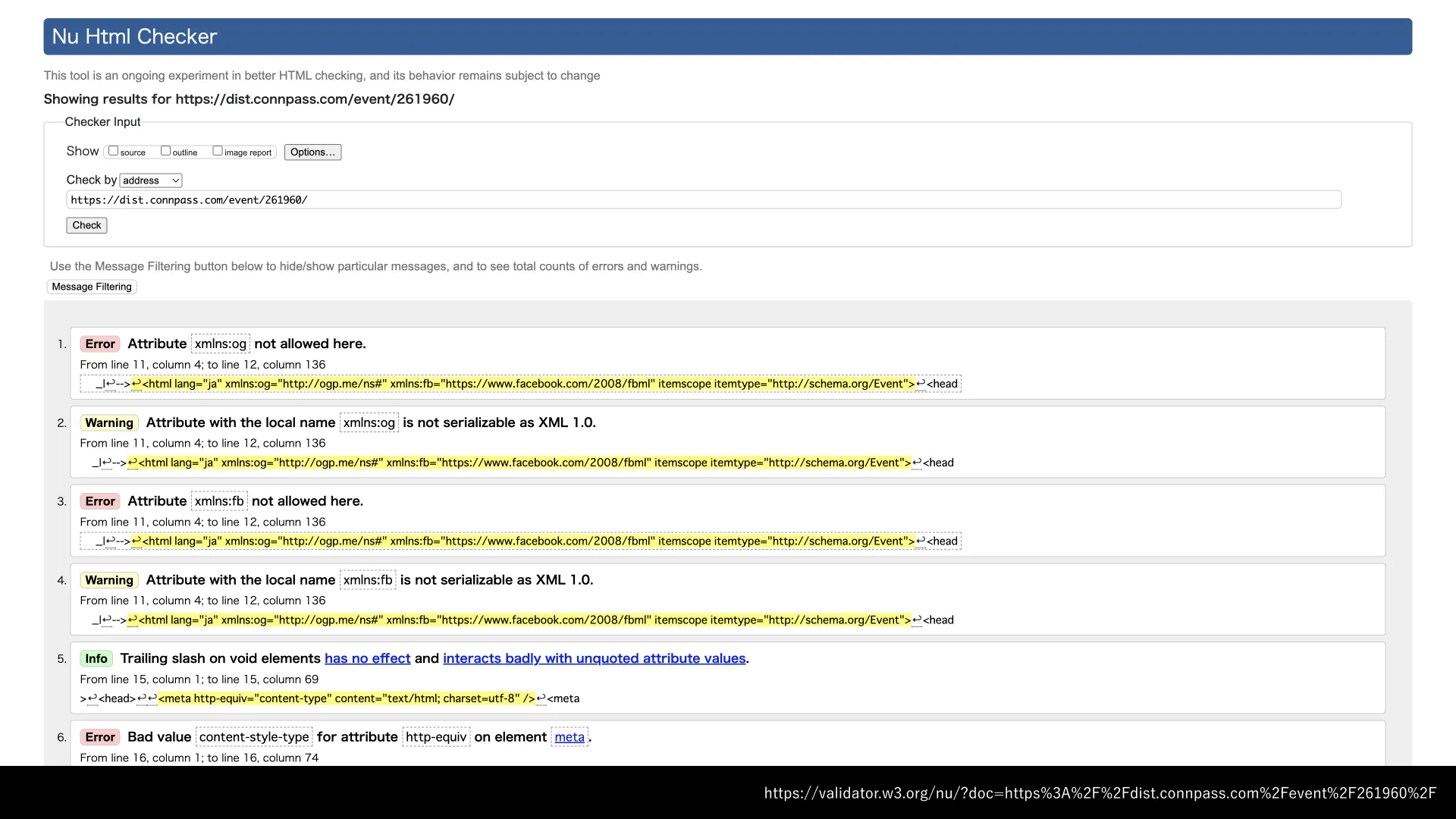
HTMLにはチェッカーがありますから、もし構文エラーをしていたり、変な属性を使っていたりすれば、チェッカーから発される警告によってそのことに気づけるようになっています。それでも、すべての間違いをチェッカーで指摘できるわけではありません。
あくまでチェッカーでわかるのは、型通りに判断できるような、明確に間違いであると言える部分についてだけです。HTML仕様の定義と照らし合わせたときに、アリかナシかをはっきり言い切れる部分についてだけチェックしている、ということです。
一方でマークアップにおいては、非常に文脈的な解釈が必要になる場面があります。HTMLの性質からして、定義の幅を狭く固定するということがなされていないので、状況に応じてその場その場の個別解を導き出すことが重要になります。したがって、個々人の考えをもって正解を決めるしかないのです。

一つ例を挙げます。私の家の近所にはインドカレー屋がありますが、その周りにはいくつか立て看板のようなものがあります。そこで、店自体をウェブサイトとして、看板はウェブページとして捉えてみると、マークアップにおいてはどのように考えて判断できるでしょうか。
最初にマークアップすべきは、看板右上にあるこの店のロゴです。明らかにこれがサイトのシンボルだと思います。ウェブサイトで言うところのヘッダーなのでheaderとしつつ、その中に入るロゴは画像なのでimgです。

<header>
<p><img src="logo.svg" alt="インド料理 ハティ" /></p>
</header>
一つポイントになるのが、そのaltの値です。ロゴとしては「HATI INDIAN RESTAURANT」と表記されていますが、altは店名として正式な表記であろう「インド料理 ハティ」とします。altの書き方についてはいくつかの考え方がありますが、基本としては、その画像をそのままテキストに置き換えてもおかしくないようにしておくのがセオリーです。
altとは代替を意味しますが、ロゴにあるのと同じ文字列に置き換えることが必ずしも代替なのではありません。そもそもは、店名の正式な表記が先にあってからロゴが後からついてくる、という主従関係になっているはずです。逆説的に言えば、むしろロゴの方が代替です。
続いて看板の左上には、大きな文字で「Take Out Menu」「お弁当メニュー」とあります。ここからはページ固有の要素と言えるでしょう。外側はmainで囲いつつ、「Take Out Menu」はh1にします。

<main>
<hgroup>
<h1 lang="en">Take Out Menu</h1>
<p>お弁当メニュー</p>
</hgroup>
...
</main>
「Take Out Menu」の下には「お弁当メニュー」の文字があります。日本語訳を併記しているようです。これらの二行はまとめてhgroupにするのがよいでしょう。場合によっては、両方のテキストをh1の中に含めてしまうのもアリですが、レイアウトの都合を考えるとこちらがベターです。
それらに続いて「インド料理のお弁当」という見出しがあり、お弁当の種類がカード状に並んでいます。カードが六つあるので、これらをulでまとめてしまうのがよさそうに見えます。

<li>
<p>A カレーライス弁当</p>
<p><img src="indian-lunchbox-a.jpg" alt="..." /></p>
<p><del>¥ 480</del> <ins>¥ 500</ins></p>
<p>A 弁当 <span lang="en">A Lunch Box</span></p>
<p>カレー1種・ライス<del>・ナン</del></p>
<p lang="en">1 Curry, Rice <del>or Nan</del></p>
</li>
<li>...</li>
<li>...</li>
<li>...</li>
ところが最後の六つ目のカードを見ると、これだけ少し違った内容になっています。それ以外のカードは、「カレーライス弁当」「インド弁当」「ナン付きカレーライス弁当」という風になっているのに、六つ目のカードだけ、「ナンお持ち帰り」「ライス・麺の大盛り」とあります。

これらは情報の種類としては別物なので、別の項目に分けて扱いたいところです。同じ項目としてまとめられていると、弁当が六種類あるように勘違いしてしまうからです。
そこでマークアップとしては、六つ目のカードだけ別のリストにできるとよさそうです。しかしそうすると、CSSでレイアウトするのが難しくなってしまうかもしれません。
<ul>
<li>...</li>
</ul>
<p><img src="indian-other.jpg" alt="..." /></p>
<ul>
<li>
<p>ナンお持帰り</p>
<p lang="en">Nan Take Out</p>
<p><del>¥ 280</del><ins>¥ 300</ins></p>
</li>
<li>...</li>
</ul>
ならば、display: contentsを使うのもアリです。こうすれば、レイアウト的にはulの存在が無視されて、その中のliが直接の子要素と同等に扱われるようになります。これでCSSとしても問題ないでしょう。
<div class="grid">
<ul style="display: contents" role="list">
<li>...</li>
</ul>
<div>
<p><img src="indian-other.jpg" alt="..." /></p>
<ul>
<li>
<p>ナンお持帰り</p>
<p lang="en">Nan Take Out</p>
<p><del>¥ 280</del><ins>¥ 300</ins></p>
</li>
<li>...</li>
</ul>
</div>
</div>
注意点としては、ulにはdisplay: contentsと同時にrole=listが指定されていることです。roleというのは、その要素がどのような役割を持つのかをスクリーンリーダーの支援技術などに対して明示するための属性です。これはHTMLとは別に、WAI-ARIAと呼ばれる仕様として定義されているものです。ulの場合、role属性を指定しなければlistの役割を持つことに決まっています。
では、なぜあえてrole=listと指定するのでしょうか。それは、現在の一部の環境においては、display: contentsを指定するとlistとして扱われなくなってしまうという不具合があるからです。ulがlistとして扱われなくなると、スクリーンリーダーのユーザーなどにとって使い勝手が良くありません。そこで、明示的にrole=listと指定することでその問題を回避できるのです。
というわけで、マークアップの際にはどういった風に考えているかという例を簡単に示してみました。それほど複雑なコンテンツではないものの、しかしながら、具体的な判断基準を言葉にしてみると、それなりにこみ入っていることがわかります。
HTMLでは、それぞれの要素などをどう使うのかは一応定義されているものの、基本的には、それによってマークアップが強く規定されるというわけではありません。定義はあるものの、緩い定義になっていて、状況に応じて柔軟な使い方ができるような余白がある。そういうイメージです。
だから、何か0か1かの判断を下せば自動的に答えが決まるわけではありません。考慮すべきさまざまな事情を踏まえて、時にはあちらを立てればこちらが立たずなジレンマを抱えながらも、それぞれの場面において最も理想的なバランスを見つけ出す。そうした姿勢が重要です。
マークアップの際に考慮すべきことは、大きく捉えると次のような種類に分けられます。
- コンテンツの性質、制作者の狙い
- HTMLのセマンティクス
- WAI-ARIAのセマンティクス
- ブラウザ・OS・スクリーンリーダーでのサポート状況、ユーザーにとっての使い勝手
- CSSやJavaScriptなど周辺技術との兼ね合い、連携のしやすさ
- ソースコードの運用性
まず、マークアップの対象である情報構造は人の手から生まれるものですから、そこには何かしらの意図や狙いがあるはずです。それを、HTMLにおいてどのように表現すべきかを考えてマークアップする必要があります。
関連するところとして、以前、HTMLの語彙を使って情報構造を考えるという発表をしたことがあります。そちらもご覧ください。

次に、HTMLのセマンティクスです。つまり、HTML仕様をよく理解した上でマークアップできているか、ということです。非常に基本的ではあるものの、簡単ではありません。仕様を素直に読み解くことは誰にでもできることではありません。
最近では、HTML仕様をわかりやすく正確に解説した書籍『HTML解体新書』がありますので、まずはこちらを読んでいただくのがおすすめです。
続いて、WAI-ARIAのセマンティクスです。WAI-ARIAはHTMLと連携した仕様であり、スクリーンリーダーなどの支援技術に対して適切な情報伝達ができるようにすることを目的としています。
ブラウザでHTML文書を表示すると、それがDOMツリーに変換された上でページが描画されます。その際同時に、DOMツリーをもとにしてアクセシビリティツリーと呼ばれる構造が生成されています。スクリーンリーダーのユーザーは、OSを経由してアクセシビリティツリーにアクセスすることによってページを利用しています。
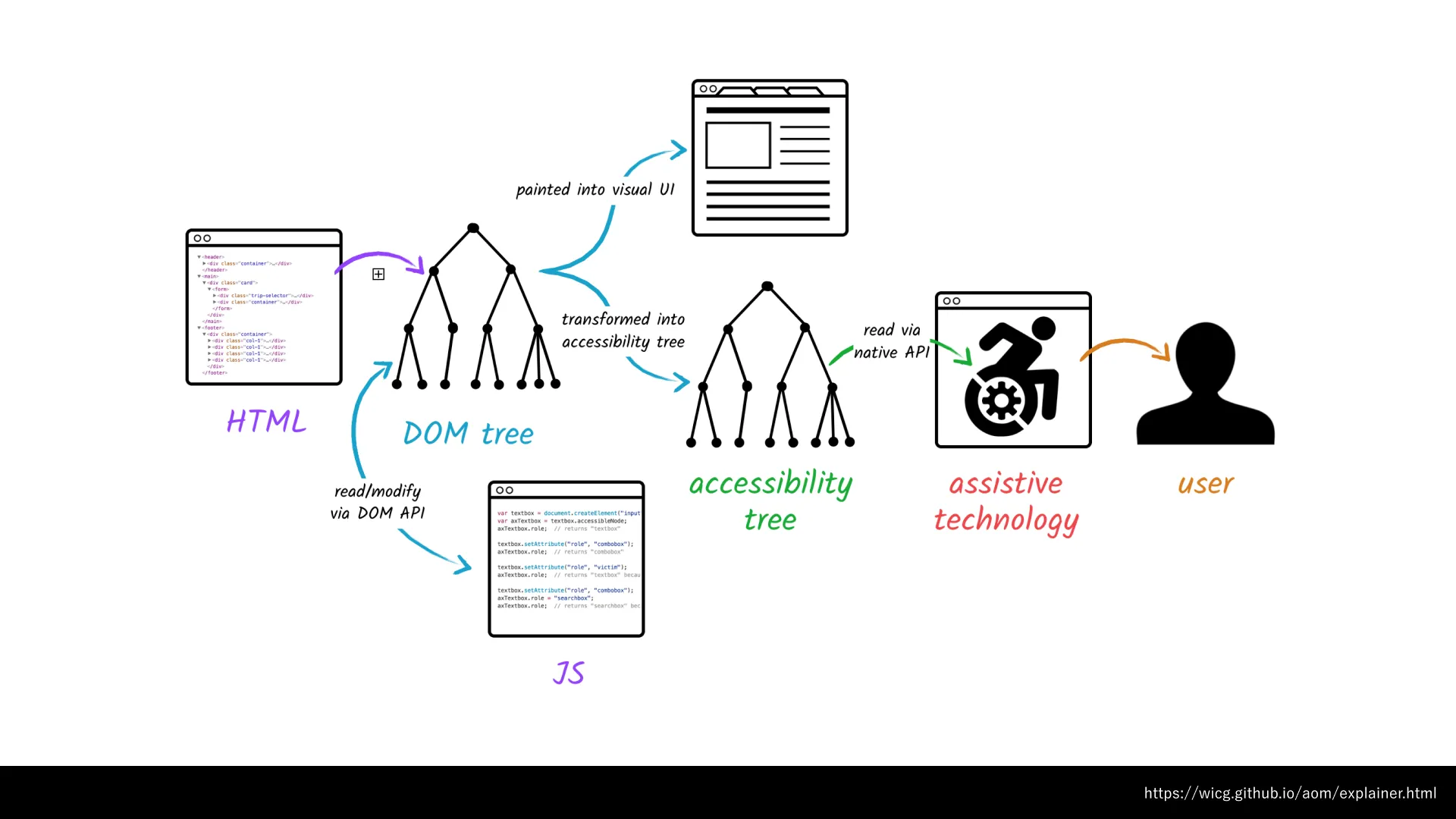
アクセシビリティツリーは、基本的にはWAI-ARIA仕様に則って生成されます。そのため、WAI-ARIAについてもよく理解しておくことが大切です。『HTML解体新書』では、WAI-ARIAについても解説されています。
WAI-ARIAの基本的なところを理解した後には、WAI-ARIAのデザインパターンに目を通してみるとよいでしょう。W3C Web Accessibility Initiativeというグループによって、WAI-ARIAを使って一般的なUIコンポーネントを実装するためのパターンが公開されています。
そして、ブラウザ・OS・スクリーンリーダーでのサポート状況、ユーザーにとっての使い勝手について。環境によって、HTMLの機能が実装されていたりされていなかったりすることがありますが、これはWAI-ARIAにおいても同じです。仕様としては存在していても、ブラウザに実装されていないから実質使えない、ということがあります。そういったことを調べられるツールとして、Can I use…のWAI-ARIA版のようなものがあります。
これによって実装状況を確認した後には、実際にその環境を使って検証するようにしてください。自分でもスクリーンリーダーを使ってみることが大切です。
そして、ある機能が実装されていたとしても、それがユーザーにとって使いやすいものになっているかどうかはまた別の問題です。さらに、個々の機能だけにかぎらず全体として、ユーザーは実際にどのような環境で操作しているのかを知っておくことは重要です。
そこで、実際に支援技術を利用する障害者がどのようにウェブページを利用しているかを紹介する動画が総務省から公開されています。まずはこれを見ていただくのがよいでしょう。
加えて、実際のユーザーの利用状況についての調査結果なども公開されています。こうしたものにも目を通しておくと参考にできることがあります。
さて次に、CSSやJavaScriptなど周辺技術との兼ね合い、連携のしやすさです。HTMLの構造によっては、CSSが書きにくくなったり、JavaScriptでの操作が難しくなったりすることがあります。あるいは、CMSの機能やWYSIWYGからの出力、テンプレートエンジンやコンポーネントシステムの性質を踏まえて、それに適した実装方法を検討することもあるはずです。そうした考慮もマークアップの一環です。
最後に、ソースコードの運用性です。たとえば、よかれと思って複雑な仕様を実装してしまった結果、メンテナンスできないほど厄介な状態になってしまうことは珍しくありません。また似たようなところでは、無理のある運用ルールを設定して誰にも守られなくなるということもあるでしょう。そうした問題を防ぐためには、ちょうどいい塩梅を探りながら開発を進めていかなければなりません。
マークアップのアプローチとして一つ頭に入れておいてほしいことがあります。それは、たとえば何か複雑に見えるものがあるとき、必ずしもそれを複雑なまま実装する必要はなく、もっとシンプルな形にしてもよいということです。
『インクルーシブHTML+CSS & JavaScript』では、いわゆるボタンリンクの実装方法について紹介されています。いわく、ボタンリンクと本当のbuttonは、同じ見た目にせずにそれぞれ別々にしてしまおう、という話です。

aとbuttonは、どちらも押せるという意味では同じですが、細かく見ていくと微妙に振る舞いが異なります。にもかかわらず、それらを同じ見た目にして同じコンポーネントであるように扱ってしまうのはやや乱暴です。機能的に異なるものを同じように扱うことで、制作者自身が混乱してしまうこともあります。
その解決策はシンプルです。別物なのだから、見た目としても別物にしてしまう。ただそれだけです。もともとあるHTMLの区分を無視して、無理やり別のことをしているから難しくなってしまうのです。
これまで話してきたのは、マークアップの複雑さについてです。考慮すべき要素がいくつもあるがゆえに、それらをうまく調整する手腕が問われるという話でした。一方、そのような「小難しいこと」を考えずに、ごく素朴な感覚をもってマークアップができるものの例として、利用規約のマークアップが挙げられます。
利用規約は、極めてシンプルなウェブページの代表です。これは言ってしまえば、「誰も読まないページ」でもあります。だからこそ、HTMLという形式に対して素直で作りやすく、ごく普通の形を保ち続けられるのだとも言えます。
利用規約のマークアップでは、ほとんど迷うことがありません。どのようにマークアップするかが明確で、簡単です。なぜならHTMLが、利用規約のような文書を表現するために適した形式になっているからです。
HTMLでは、情報を表現するために使える語彙があらかじめ決められています。そのため、それに合ったものは作りやすく、合わないものは作りづらくなります。どのようなウェブページを作るにしても、そこから逃れることはできません。ではそもそも、どうしてこうなったのでしょうか。
ティム・バーナーズ゠リー『Webの創成』によれば、HTMLの始まりは次のような考えで作られたと言います。
私は、あらゆる種類のデータのフォーマット形式がWeb上に存在することになるだろうと予測していた。一方で、そこには誰でもが使える簡単な共通語が必要であるとも感じていた。(中略)すなわち、メニュー、ヘルプ・ファイルのような簡単な文書、会議録、メール、すなわちたいていの人の日常生活の用事の95%をカバーするような仕事である。これが、HTMLすなわちハイパー・テキスト・マークアップランゲージである。
ウェブで扱われることになるであろうあらゆるタイプのドキュメント、それはたとえば、ビデオ、CAD、音声、アニメ、実行可能なコンピュータプログラムといったものを繋ぐための「糸」として、HTMLが機能することが期待されていました。
1991年当時のHTMLで使われていたタグは次のようなものです。
<TITLE> ... </TITLE>
<NEXTID 27>
<A NAME=xxx HREF=XXX> ... </A>
<ISINDEX>
<PLAINTEXT>
<LISTING>
...
</LISTING>
<P>
<H1>, <H2>, <H3>, <H4>, <H5>, <H6>
<H2>Second level heading</h2>
<ADDRESS> text ... </ADDRESS>
<HP1>...</HP1> <HP2>... </HP2> etc.
<DL>
<DT>Term<DD>definition pagagraph
<DT>Term2<DD>Definition of term2
</DL>
<UL>
<LI> list element
<LI> another list element ...
</UL>
いくつか見慣れないタグはあるものの、現在でも当たり前に使われているものがいくつも含まれているのは驚くべきことです。見出しレベルが1から6までなのも最初から決まっていました。
『Webの創成』には、続けて次のようにあります。
世界中の人々に新しい地球規模の情報システムを使わせることが困難であることは知っていたので、私はできる限りすべてのグループを議論の場にひきずり出したかったのだ。マークアップ・ランゲージという分野がすでに存在していて、standard generlized markup language(SGML)がすでに世界の文書作成に関わる人々の間で好んで使われていた。また、当時はハイパーテキスト作成に関わる人々の間でも、これが唯一可能性のある文書作成の標準システムであると考えられていた。私はHTMLを開発するにあたり、SGMLの親戚のように見えるようにつくった。
山型のついたタグという表現も、要素や属性としてデータの種類をマークアップする考え方も、SGMLを参考にしてできたものでした。しかし大きく違うのは、SGMLはその用途があらかじめ決められているわけではない、というところです。HTMLはウェブページの作成を目的とした言語ですが、SGMLはあらゆる情報をマークアップするための言語です。SGMLの作業は、個々の目的に応じた文書を分析するところから始まります。
『SGML入門』では、教科書の前付けページの構成例が紹介されています。教科書の前付けページに含まれるデータを分析して、ツリーダイアグラムとして構造を定義したものです。
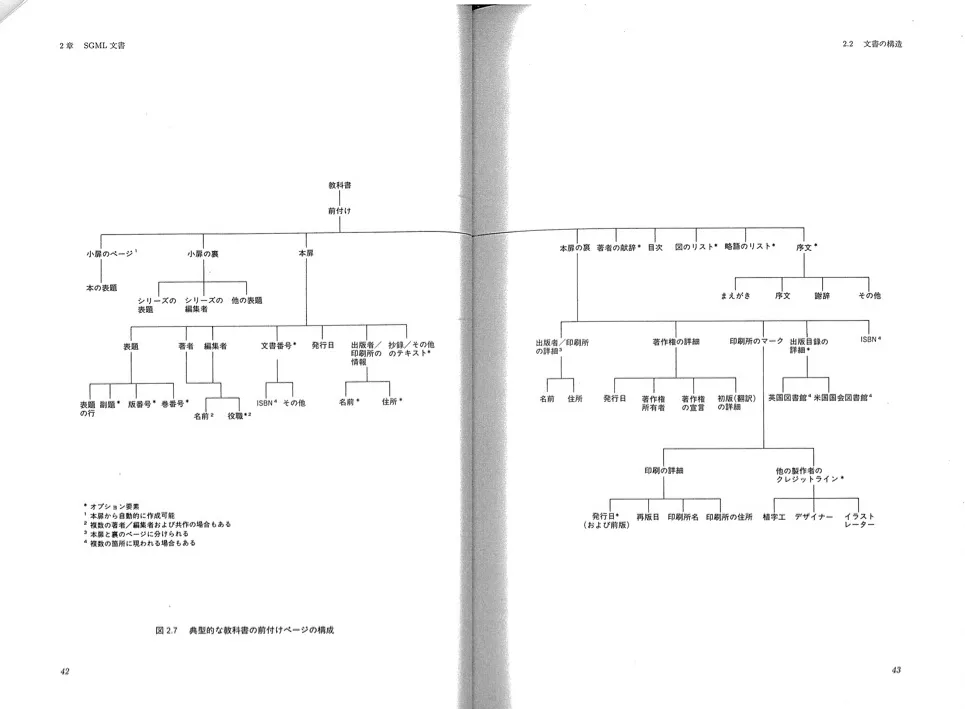
- 教科書
- 前付け
- 小扉のページ 1
- 本の表題
- 小扉の裏
- シリーズの表題
- シリーズの編集者
- 他の表題
- 本扉
- 表題
- 表題の行
- 副題 ※
- 版番号 ※
- 巻番号 ※
- 著者
- 名前 2
- 役職 ※2
- 編集者
- 名前
- 役職
- 文書番号 ※
- ISBN 4
- その他
- 発行日
- 出版社/印刷所の情報
- 名前 ※
- 住所 ※
- 抄録/その他のテキスト ※
- 表題
- 本扉の裏
- 出版社/印刷所の詳細 3
- 名前
- 住所
- 著作権の詳細
- 発行日
- 著作権所有者
- 著作権の宣言
- 初版(翻訳)の詳細
- 印刷所のマーク
- 印刷の詳細
- 発行日(および前版) ※
- 再版日
- 印刷所名
- 印刷所の住所
- 他の製作者のクレジットライン ※
- 植字工
- デザイナー
- イラストレーター
- 印刷の詳細
- 出版目録の詳細 ※
- 英国図書館 4
- 米国国会図書館 4
- ISBN 4
- 出版社/印刷所の詳細 3
- 著者の献辞 ※
- 目次
- 図のリスト ※
- 略語のリスト ※
- 序文 ※
- まえがき
- 序文
- 謝辞
- その他
- 小扉のページ 1
- 前付け
※ オプション要素
1 本扉から自動的に作成可能
2 複数の著者/編集者および共作の場合もある
3 本扉と裏のページに分けられる
4 複数の箇所に現れる場合もある
もう少し親しみやすい例としては、『SGML実践ガイド』では、料理のレシピをマークアップするための要素の例も紹介されていました。

『SGML実践ガイド』によれば、SGMLの文書を定義するに当たっては、次の3つの基本的な観点があります。
- 書式
- 構造
- 内容
要素のスタイルまたは体裁にもとづいてタグをつけていくことを書式タグ付けと呼びます。対象となるのは、テキスト内の一部の言葉だけを太字にする強調部分などです。表も書式に大きく依存した要素です。書式タグに頼りすぎると、データを他の目的に転用するのが難しくなります。
<head1 q='left' w='bold'>This is a heading that is quad left and
bold
<p in='1em' type='bold'>This is an indented paragraph
The author wants to <emphasis/emphasize/ this word.
次に、総称的な階層にもとづいてタグをつけていくことを構造タグ付けと呼びます。要素には、階層内の順列を表す名前をつけます。
<head1>This is a First Level Head
<head2>This is a Second Level Head
<para0>This is a high-level paragraph
<list1>This is a first-level indented list item
<list2>This is a second-level indented list item
最後に、体裁や階層構造にとらわれず、要素の内容(目的)にもとづいてタグをつけるのが内容タグ付けです。
<lesson>How to peel an egg
<intro>In this lesson, we will present the best ways to peel
two kinds of eggs.
</intro>
<obj>Successfully peel a hard-boiled egg</obj>
<obj>Successfully peel a raw egg</obj>
内容タグは使いすぎないように注意します。データとして別物であると意識しすぎて違うタグを使いたくなっても、実は、区別しなくても処理には差し支えないということがよくあるからです。
内容タグの例としては次のようなものがあります。
- Techinical Manual
<part>: Part Number<mod>: Model<chkl>: Checklist<cau>: Caution
- Computer Manuals
<command>: Command<opt>: Option<parm>: Parameter<key>: Keystroke
- Training Manual
<les>: Lesson<obj>: Objectives<ex>:Exercise<def>: Definition
- General
<fw>: Foreign Word<name>: Name<gl>: Glossary Word<xref>: Cross Reference
- Periodicals
<au>: Author<hl>: Headline<en>: End Note<blurb>: Blurb
- Legal
<case>: Case Cite<reg>: Reg Cite<code>: Code Cite<squib>: Squib
これら3つの観点をバランスよく組み合わせて定義するのが理想的であるそうです。
現在あるHTML要素と照らし合わせてみると、まさにこの3つの観点が存在することがわかります。HTML5では定義が改められたb要素やi要素なども、もとは明らかに書式タグ付けを意識しています。
先述の通り、HTMLではこうして要素を定義するフェーズは通過済みで、ユーザーが使うときには定義を参照しながらマークアップするだけの状態になっています。これはつまり、「ウェブページとはこういうものだ」という思考の枠組みが決められているとも言えます。だからこそ、それに合わせて発想しさえすれば簡単にマークアップはできるわけですが、それができなければ難儀するかもしれません。
はたまた、HTML仕様は変化し続けています。定義が決まっていると言っても不変ではありません。なぜなら、より多くのユースケースがウェブに求められているためです。時には、ユーザーが想定外の使い方をすることで新しい可能性が見い出されては、それに適応するように仕様が書き変わってきました。価値は変わりゆくものです。かつてはナシだったものが、今はアリになっている。そしてそれは、一時の逸脱によってもたらされます。
HTMLのマークアップは保守的な営みです。問題が起こらないように、意味が損なわれないように、複数の文脈を繋ぎ止める役割をします。これは見方によっては、過去と現在を接続する言語だと捉えられます。
変化は必然ですが、同時に、人は過去に依存して生きています。過去の選択が今を作っています。覆すことはできません。これを理解し、受け入れて、今を成り立たせていくことこそが、マークアップの意義であると思います。
